 |
Un cluster podemos entenderlo como:
Un conjunto de máquinas unidas por una red de comunicación trabajando por
un servicio conjunto.
Según el servicio puede ser dar alta disponibilidad, alto rendimiento, etc...
Por supuesto esta definición no es estricta, de hecho uno de los problemas
que tiene es que es demasiado vaga porque por ejemplo dos
consolas de videojuegos conectadas para jugar en red ¿se considera cluster? Pero si en vez
de estar jugando se está usando el kit de GNU/Linux haciendo procesamiento
paralelo ¿entonces se podría considerar cluster?
Realmente el cambio de ambiente es mínimo, desde luego a nadie se le ocurriría definir cluster en base al contenido de los programas que se ejecuten y de hecho es posible que los juegos tengan más capacidades de procesamiento distribuido que los propios programas, entonces ¿qué es un cluster?
Hay definiciones que distinguen entre cluster de máquinas SMP y clusters formados por nodos monoprocesadores. Hay arquitecturas clusters que se denominan constelaciones4.1 y se caracterizan por que cada nodo contiene más procesadores que el número de nodos. A pesar de todo, las constelaciones siguen siendo clusters de componentes o nodos aventajados y caros. De hecho entre las máquinas que aparecen en el top500 existen unos pocos clusters que pertenecen a organizaciones que no son gigantes de la informática, lo cual indica el precio que pueden llegar a tener estos sistemas.
Por poner unos ejemplos de la disparidad de opiniones que existen, se adjuntan las definiciones que dan ciertas autoridades de esta materia:
Un cluster consiste en un conjunto de máquinas y un servidor de cluster
dedicado, para realizar los relativamente infrecuentes accesos a los recursos
de otros procesos, se accede al servidor de cluster de cada grupo
del libro Operating System Concepts de Silberschatz Galvin.
Un cluster es la variación de bajo precio de un multiprocesador masivamente
paralelo (miles de procesadores, memoria distribuida, red de baja latencia),
con las siguientes diferencias: cada nodo es una máquina quizás sin algo
del hardware (monitor, teclado, mouse, etc.), el nodo podría ser SMP.
Los nodos se conectan por una red de bajo precio como Ethernet o ATM aunque
en clusters comerciales se pueden usar tecnologías de red propias.
El interfaz de red no está muy acoplado al bus I/O.
Todos los nodos tienen disco local.
Cada nodo tiene un sistema operativo UNIX con una capa de software
para soportar todas las características del cluster del libro
Scalable Parallel Computing de Kai Hwang y Khiwei Xu.
Es una clase de arquitectura de computador paralelo que se basa en unir
máquinas independientes cooperativas integradas por medio de redes de interconexión
para proveer un sistema coordinado, capaz de procesar una
carga del autor Dr. Thomas Sterling.
Para crear un cluster se necesitan al menos dos nodos. Una de las características principales de estas arquitecturas es que exista un medio de comunicación (red) donde los procesos puedan migrar para computarse en diferentes estaciones paralelamente. Un solo nodo no cumple este requerimiento por su condición de aislamiento para poder compartir información. Las arqutecturas con varios procesadores en placa tampoco son consideradas clusters, bien sean máquinas SMP o mainframes, debido a que el bus de comunicación no suele ser de red, sino interno.
Por esta razón se deduce la primera característica de un cluster:
i.- Un cluster consta de 2 o más nodos.
Los nodos necesitan estar conectados para llevar a cabo
su misión. Por tanto:
ii.- Los nodos de un cluster están conectados entre sí por al menos un canal de comunicación.
Por ahora se ha referenciado a las características físicas de un cluster, que
son las características sobre las que más consenso hay.
Pero existen más problemas sobre las características del programario de control que
se ejecuta, pues es el software el que finalmente
dotará al conjunto de máquinas de capacidad para migrar procesos,
balancear la carga en cada nodo, etc.
y iii.- Los clusters necesitan software de control especializado.
El problema también se plantea por los distintos tipos de clusters, cada
uno de ellos requiere un modelado y diseño del software distinto.
Como es obvio las características del cluster son completamente dependientes del software, por lo que no se tratarán las funcionalidades del software sino el modelo general de software que compone un cluster.
Para empezar, parte de este software se debe dedicar a la comunicación entre los nodos. Existen varios tipos de software que pueden conformar un cluster:
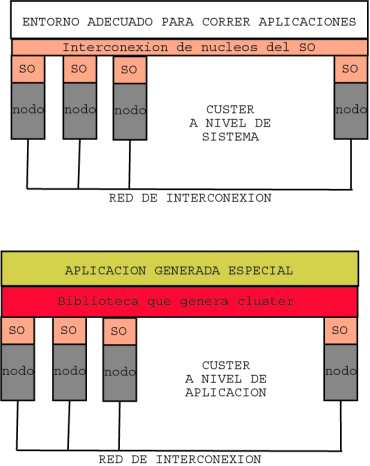
Este tipo de software se sitúa a nivel de aplicacion, se utilizan generalmente bibliotecas de carácter general que permiten la abstracción de un nodo a un sistema conjunto, permitiendo crear aplicaciones en un entorno distribuido de manera lo más abstracta posible. Este tipo de software suele generar elementos de proceso del tipo rutinas, procesos o tareas, que se ejecutan en cada nodo del cluster y se comunican entre sí a través de la red.
Este tipo de software se sitúa a nivel de sistema, suele estar implementado como parte del sistema operativo de cada nodo, o ser la totalidad de éste.
Es más crítico y complejo, por otro lado suele resolver problemas de carácter más general que los anteriores y su eficiencia, por norma general, es mayor.
Se entiende por acoplamiento del software a la integración que tengan todos los elementos software que existan en cada nodo. Gran parte de la integración del sistema la produce la comunicación entre los nodos, y es por esta razón por la que se define el acoplamiento; otra parte es la que implica cómo de crítico es el software y su capacidad de recuperación ante fallos.
Aquí hay que hacer un pequeño inciso para destacar que todo esto depende de si el sistema es centralizado o distribuido. En cualquier caso, el acoplamiento del software es una medida subjetiva basada en la integración de un sistema cluster a nivel general.
Se distingue entre 3 tipos de acoplamiento:
Acoplamiento fuerte.
El software que entra en este grupo es software cuyos elementos se interrelacionan mucho unos con otros y posibilitan la mayoría de las funcionalidades del cluster de manera altamente cooperativa. El caso de acoplamiento más fuerte que se puede dar es que solamente haya una imagen del kernel del sistema operativo, distribuida entre un conjunto de nodos que la compartirán. Por supuesto algo fundamental es poder acceder a todas las partes de este sistema operativo, estrechamente relacionadas entre sí y distribuidas entre los nodos.
Este caso es el que se considera como más acoplado, de hecho no está catalogado como cluster, sino como sistema operativo distribuido.
Otro ejemplo son los cluster SSI, en estos clusters todos los nodos ven una misma imagen del sistema, pero todos los nodos tienen su propio sistema operativo, aunque estos sistemas están estrechamente relacionados para dar la sensación a las aplicaciones que todos los nodos son idénticos y se acceda de una manera homogénea a los recursos del sistema total.
Si arranca o ejecuta una aplicación, ésta verá un sistema homogéneo, por lo tanto los kernels tienen que conocer los recursos de otros nodos para presentarle al sistema local los recursos que encontraría si estuviera en otro nodo. Por supuesto se necesita un sistema de nombres único, manejado de sistema distribuida o centralizada y un mapeo de los recursos físicos a este sistema de nombres.
Acoplamiento medio.
A este grupo pertenece un software que no necesita un conocimiento tan exhaustivo de todos los recursos de otros nodos, pero que sigue usando el software de otros nodos para aplicaciones de muy bajo nivel. Como ejemplos hay openMosix y Linux-HA.
Un cluster openMosix necesita que todos los kernels sean de la misma versión. Por otro lado no está tan acoplado como el caso anterior: no necesita un sistema de nombres común en todos los nodos, y su capacidad de dividir los procesos en una parte local y otra remota consigue que por un lado se necesite el software del otro nodo donde está la parte del fichero que falta en el nodo local y por otro que no se necesite un SSI para hacer otras tareas.
Acoplamiento débil.
Generalmente se basan en aplicaciones construidas por bibliotecas preparadas para aplicaciones distribuidas. Es el caso de por ejemplo PVM, MPI o CORBA. Éstos por sí mismos no funcionan en modo alguno con las características que antes se han descrito (como Beowulf) y hay que dotarles de una estructura superior que utilice las capacidades del cluster para que éste funcione.
En general la catalogación de los clusters se hace en base a cuatro factores de diseño bastante ortogonales entre sí :
Por otro lado está el factor de control del cluster. El parámetro de control implica el modelo de gestión que propone el cluster. Este modelo de gestión hace referencia a la manera de configurar el cluster y es dependiente del modelo de conexionado o colaboración que surgen entre los nodos. Puede ser de dos tipos:
Es propio de sistemas distribuidos, como ventaja tiene que presenta más tolerancia a fallos como sistema global, y como desventajas que la gestión y administración de los equipos requiere más tiempo.
Homogeneidad de un cluster
Por otro lado esta la distribución de riesgos. La mayoría de los usuarios tienen sus servicios, aplicaciones, bases de datos o recursos en un solo ordenador, o dependientes de un solo ordenador. Otro paso más adelante es colocar las bases de datos replicadas sobre sistemas de archivos distribuidos de manera que estos no se pierdan por que los datos son un recurso importante. Actualmente el mercado de la informática exige no solo que los datos sean críticos sino que los servicios estén activos constantemente. Esto exige medios y técnicas que permitan que el tiempo en el que una máquina esté inactiva sea el menor posible. La distribución de factores de riesgo a lo largo de un cluster (o la distribución de funcionalidades en casos más generales) permite de una forma única obtener la funcionalidad de una manera más confiable: si una máquina cae otras podrán dar el servicio.
Por último está el factor de escalabilidad, del cual se habló en el tema de introducción. Cuanto más escalable es un sistema menos costará mejorar el rendimiento, lo cual abarata el coste, y en el caso de que el cluster lo implemente distribuye más el riesgo de caída de un sistema.
En cualquier caso, todas estas características dan pie a los tipos de clusters que se van a ver.
Alto rendimiento (HP, high performance)
Los clusters de alto rendimiento han sido creados para compartir el recurso más valioso de un ordenador, es decir, el tiempo de proceso. Cualquier operación que necesite altos tiempos de CPU puede ser utilizada en un cluster de alto rendimiento, siempre que se encuentre un algoritmo que sea paralelizable.
Existen clusters que pueden ser denominados de alto rendimiento tanto a nivel de sistema como a nivel de aplicacion. A nivel de sistema tenemos openMosix, mientras que a nivel de aplicación se encuentran otros como MPI, PVM, Beowulf y otros muchos. En cualquier caso, estos clusters hacen uso de la capacidad de procesamiento que pueden tener varias máquinas.
Alta disponibilidad (HA, high availability)
Los clusters de alta disponibilidad son bastante ortogonales en lo que se refieren a funcionalidad a un cluster de alto rendimiento. Los clusters de alta disponibilidad pretenden dar servicios 7/24 de cualquier tipo, son clusters donde la principal funcionalidad es estar controlando y actuando para que un servicio o varios se encuentren activos durante el máximo periodo de tiempo posible. En estos casos se puede comprobar como la monitorización de otros es parte de la colaboración entre los nodos del cluster.
Alta confiabilidad (HR, high reliability)
Por ultimo, están los clusters de alta confiabilidad. Estos clusters tratan de aportar la máxima confiabilidad en un entorno, en la cual se necesite saber que el sistema se va a comportar de una manera determinada. Puede tratarse por ejemplo de sistemas de respeusta a tiempo real.
Pueden existir otras catalogaciones en lo que se refiere a tipos de clusters,
en nuestro caso, solamente hemos considerado las tres que más clusters
implementados engloban, si bien existe alguno de ellos que puede ser considerar
o como cluster de varios tipos a la vez.
Dentro de esta definición no se engloba ningún tipo de problema en concreto. Esto supone que cualquier cluster que haga que el rendimiento del sistema aumente respecto al de uno de los nodos individuales puede ser considerado cluster HP.
Los clusters implementados a nivel de aplicacion no suelen implementar balanceo de carga. Suelen basar todo su funcionamiento en una política de localización que sitúa las tareas en los diferentes nodos del cluster, y las comunica mediante las librerías abstractas. Resuelven problemas de cualquier tipo de los que se han visto en el apartado anterior, pero se deben diseñar y codificar aplicaciones propias para cada tipo para poderlas utilizar en estos clusters.
Por otro lado están los sistemas de alto rendimiento implementados a nivel de sistema. Estos clusters basan todo su funcionamiento en comunicación y colaboración de los nodos a nivel de sistema operativo, lo que implica generalmente que son clusters de nodos de la misma arquitectura, con ventajas en lo que se refiere al factor de acoplamiento, y que basan su funcionamiento en compartición de recursos a cualquier nivel, balanceo de la carga de manera dinámica, funciones de planificación especiales y otros tantos factores que componen el sistema. Se intentan acercar a sistemas SSI, el problema está en que para obtener un sistema SSI hay que ceder en el apartado de compatibilidad con los sistemas actuales, por lo cual se suele llegar a un factor de compromiso.
Entre las limitaciones que existen actualmente está la incapacidad de balancear la carga dinámica de las librerías PVM o la incapacidad de openMosix de migrar procesos que hacen uso de memoria compartida. Una técnica que obtiene mayor ventaja es cruzar ambos sistemas: PVM + openMosix. Se obtiene un sistema con un factor de acoplamiento elevado que presta las ventajas de uno y otro, con una pequeña limitación por desventajas de cada uno.
Entre los problemas que solucionan se encuentran:
Se basan en principios muy simples que pueden ser desarrollados hasta crear sistemas complejos especializados para cada entorno particular. En cualquier caso, las técnicas de estos sistemas suelen basarse en excluir del sistema aquellos puntos críticos que pueden producir un fallo y por tanto la pérdida de disponibilidad de un servicio. Para esto se suelen implementar desde enlaces de red redundantes hasta disponer de N máquinas para hacer una misma tarea de manera que si caen N-1 máquinas el servicio permanece activo sin pérdida de rendimiento.
La explicación de estas técnicas ha sido muy somera, se darán con más detalle en el caítulo perteneciente a clusters HA.
Dar a un cluster SSI capacidad de alta confiabilidad implica gastar recursos necesarios para evitar que aplicaciones caigan. Aquí hay que hacer de nuevo un inciso.
En los clusters de alta disponibilidad generalmente una vez que el servicio ha caído éste se relanza, y no existe manera de conservar el estado del servidor anterior, más que mediante puntos de parada o checkpoints, pero que en conexiones en tiempo real no suelen ser suficientes. Por otro lado, los clusters confiables tratan de mantener el estado de las aplicaciones, no simplemente de utilizar el ultimo checkpoint del sistema y relanzar el servicio.
Generalmente este tipo de clusters suele ser utilizado para entornos de tipo empresarial y esta funcionalidad solamente puede ser efectuada por hardware especializado. Por elmomento no existe ninguno de estos clusters implementados como software. Esto se debe a limitaciones de la latencia de la red, así como a la complejidad de mantener los estados.
Se hacen necesarias características de cluster SSI, tener un único reloj de sistema conjunto y otras más. Dada la naturaleza asíncrona actual en el campo de los clusters, este tipo de clusters aún será difícil de implementar hasta que no se abaraten las técnicas de comunicación.