| Siguiente: Detalles de implementación Superior: Mejorando NFS Anterior: Introducción básica a NFS |
Nuestro objetivo, pues, era añadir una operación llamada copy que tuviese iguales resultados que read y write, que cumpliese las restricciones de diseño de NFS y que, a ser posible, fuese compatible hacia atrás con los servidores y clientes sin modificar.
Para ello tuvimos que modificar dos elementos, por un lado el cliente, dentro del kernel, (para lo que utilizamos la versión 2.2.12 del kernel de Linux) para dar acceso a nuestra nueva operación. Por otro lado, tuvimos que modificar también el servidor de NFS para atenderla (para lo que utilizamos la versión 2.2beta37, un servidor de espacio de usuario, pues el de espacio de kernel estaba todavía en estado experimental).
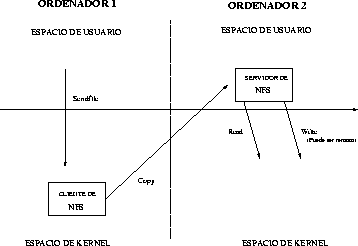
Aunque en un principio pensamos en crear una nueva llamada al sistema para dar acceso a nuestra operación, finalmente nos dimos cuenta de que existe una operación con un interfaz idéntico al que queríamos construir, pero diseñada para trabajar en local. Se llama sendfile y copia de un descriptor de fichero a otro. Fue diseñada con sockets y servidores web en mente, para resolver un problema homomorfo al que nosotros intentábamos resolver. Sirve para evitar cambios de dominio al servir paginas web, copiando de un fichero a un socket sin cambiar de dominio (entre kernel y usuario) ni utilizar memoria innecesariamente.
Tras adoptar la llamada al sistema sendfile, la arquitectura quedó más o menos clara. El punto de entrada en el kernel era la llamada a sendfile, que a su vez llama a una operación del fichero llamada copy si está definida. Esta operación solo esta definida si el fichero es de NFS. La operación de copy llama a la RPC del mismo nombre. El servidor atiende a la petición haciendo read y write de forma local. Si el fichero no es de NFS se copia normalmente, como si se hubiese llamado a sendfile sin que esta tuviese ninguna de nuestras modificaciones.
Si hemos modificado el servidor, pero el cliente es un cliente normal de NFS, simplemente nadie llamará a la operación de copy y no habrá ningún problema.
El problema real aparece cuando es el cliente el que ha sido modificado y no existe esa operación en el servidor. En este caso, si no hubiésemos hecho nada, la RPC habría vuelto con un IO error y el cliente se habría quedado reintentando.
Con el fin de resolver este problema, hemos hecho que io error sea sinónimo de operación no implementada. En el caso de un io error, la operación de copy se deshabilita y el cliente deja de usarla, volviéndose automáticamente compatible hacia atrás. Si el error era realmente un io error, el segundo intento fallará y se comportará como el cliente de NFS sin modificar.
Hay un problema con esta aproximación y es que si realmente hay un io error, la operación de copy deja de usarse. La solución a esto sería mantener una cache con el estado del ordenador remoto, mirando si se ha usado o no la operación de copy y si responde a la operación nula (con el fin de si realmente hay un io error) en caso afirmativo.
En el estado actual la operación de copy se deshabilita y habría que volverla habilitar. Esto se puede conseguir haciendo uso de un fichero que creamos en /proc. Aun así, es cierto que se pueden causar problemas en redes con un alto índice de errores, en las que simplemente dejaría de usarse la operación copy.