|
|
![[Photo of the Author]](../../common/images2/iznoT2.png)
von Iznogood <iznogood/at/iznogood-factory.org> Über den Autor: Schon seit einiger Zeit mit GNU/Linux befasst, benutze ich nun ein Debian-System. Trotz elektronischer Studien habe ich überwiegend Übersetzungsarbeiten für die GNU/Linux-Gemeinschaft gemacht. |
Werkzeuge für die Umwandlung von Papier nach HTMLZusammenfassung:
Hier geht es um eine Werkzeugkette zur Umwandlung eines herkömmlichen Papiermagazins in HTML. Ich werde den Prozess vom Scannen bis zur HTMLifizierung erläutern.
|
Ich habe gelesen, das einige US-Universitäten es Google erlauben und dabei helfen, ihre Bibliothek in numerischer Form zu digitalisieren. Ich bin nicht Google und ich verfüge nicht über eine Universitätsbibliothek, aber ich besitze einige alte Papermagazine über Elektronik. Die Papierqualität war nicht die beste: Seiten lösen sich, das Papier graut ...
Daher habe ich mich entschlossen, es zu digitalisieren, denn obwohl die Ausgaben vor 10 Jahren stoppten, sind einige Artikel immer noch aktuell!
Am Anfang musste ich die Daten in den Computer bringen. Ein Scanner ermöglicht mir dies: nach einigen Kompatabilitätsprüfungen kaufte ich einen alten gebrauchten, aber billigen ScanJet 4300C, und nach einiger Internetnavigation fand ich die erforderlichen Einstellungen zur Konfiguration.
Unter Debian installierte ich sane, xsane, gocr und gtk-ocr ganz normal mit:
apt-get install sane xsane gocr gtk-ocrals root.
sane-find-scannerdann wechselte ich nach /etc/sane.d/, um einige Dateien zu editieren:
hp niashund alles andere wurde auskommentiert.
/dev/usb/scanner0 option connect-deviceund alles andere wurde auskommentiert.
chgrp scanner scanner0und fügte iznogood als Anwender hinzu, um mir die Benutzung des Scanners zu ermöglichen, ohne root zu sein:
adduser iznogood scannerNach einem Reboot war alles erledigt!
append="hdb=ide-scsi ignore hdb"dann ein Aufruf von
liloum es zu aktualisieren.
/dev/sdc0 /dvdrom iso9660 user, noauto 0 0hinzu. Dann änderte ich die Gruppe scd0 auf cdrom
chgrp cdrom scd0Recht einfach.
Zur Fortsetzung des Prozesses benötige ich einige Software:
sane, xsane, gimp, gocr, gtk-ocr, einen Text-Editor, einen HTML-Editor und etwas Plattenplatz.
Sane ist das Scan-Programm und xsane ist die grafische Oberfläche.
Meine Vorstellung war, die maximale Auflösung beizubehalten und damit eine 50 MB-Datei für eine Seite zu erhalten, sie zur weiteren Verarbeitung auf Platte zu speichern und nach der Fertigstellung auf
eine DVD-ROM zu brennen.
Ich setzte die Auflösung auf 600 dpi, etwas mehr Helligkeit und startete die Umwandlung. Da dies auf einem sehr altem Rechner (PII 350 MHz) lief, dauerte es etwas, aber ich erhielt ein gutes und
präzises Bild. Ich speicherte es im png-Format.
Warum solch eine Auflösung und eine 50 MB-Datei? Ich wollte eine maximale Auflösung für das Archiv und für weitere digitale Verarbeitung.
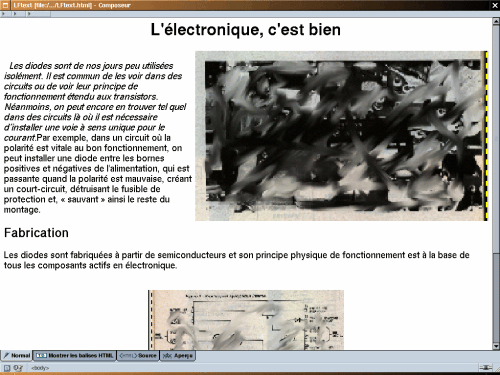
Mittels Gimp schnitt ich die Seite in grafische Bilder und Bilder, die nur den eingescannten Text enthielten.
Die Grafiken wurden mit einer reduzierten Größe in png gespeichert, damit sie auf eine HTML-Seite passen und die Textabbilder wurden nicht reduziert, aber von Farbe auf Grauwerte geändert (Werkzeuge, Farbwerkzeuge, Schwellwert und OK) und für die weitere Verarbeitung mit der OCR-Software unter der .pcx-Erweiterung gespeichert.

cat *.txt > test.txterhalte ich eine Datei test.txt und kann mit einem Texteditor einige Anpassungen vornehmen (nicht französische Zeichen entfernt, Worte korrigiert ...).
Ich erinnere mich an einen Mathe-Lehrer, der mir, als ich jung wahr, folgende Maxime erzählte:
"Um faul zu sein, muss man intelligent sein".
Ok, ich wurde faul!!!! ;-)
Es gibt einige manuelle Aufgaben, die nicht leicht zu automatisieren sind (Verzeichnis-Erstellung, Scannen, Gimp-Ausschnitte und Dateierstellung). Der Rest kann automatisiert werden.
Es gibt ein fabelhaftes englisches Tutorial über Bash-Skripting, ABS (Advanced Bash Scripting Guide),
und ich fand eine französische Übersetzung.
Sie finden die englische Version unter www.tldp.org.
Dieses Handbuch ermöglichte mir das Schreiben eines kleinen Programmes. Hier ist das Skript:
#!/bin/bash REPERTOIRE=$(pwd) cd $REPERTOIRE mkdir ../ima mv *.png ../ima/ for i in `ls *` do gocr -f UTF8 -i $i -o $i.txt done cd .. mv ima/ $REPERTOIRE cd $REPERTOIRE cat *.txt | sed -e 's/_//g' -e 's/(PICTURE)//g' -e 's/ì/i/g' \ -e 's/í/i/g' -e 's/F/r/g' -e 's/î/i/g' > test.txt
ocr-rppwd übergibt den Verzeichnispfad an das Skript, dann wird ima ausserhalb des Verzeichnisses angelegt und alle .png-Dateien dorthin verschoben. Alle Textdateien werden aufgelistet, mit gocr bearbeitet, in test.txt zusammengefasst und zur Anpassung französischer Zeichen bearbeitet.
|
Der LinuxFocus Redaktion schreiben
© Iznogood "some rights reserved" see linuxfocus.org/license/ http://www.LinuxFocus.org |
Autoren und Übersetzer:
|
2005-07-22, generated by lfparser_pdf version 2.51