Hello
Hi, I received this message but I have no way to check its accuracy. Since you sent in the Sanskrit example, can you tell me if this person is right or wrong? Thanks
<quote>
The Sanskrit translation on http://www.columbia.edu/kermit/utf8.html has two characters in the wrong place. Instead of nopahinasti, you have
nopihanista.
<end of quote>
I think that Jamie Norrish does not see on his screen what I actually wrote. It may occur with some browsers. Since the devanāgarī is not read the way it's written (as Arabic, in a certain way), a good software should decode devanāgarī as it must be read by interpreting some sequences of letters that must be read backward of replace some combinations of letters by a single ligature. Most don't.
Let us take the case of letter [i], written ि before the letter it actually follows when the word is read aloud. For instance, [bi] appears as िब (i « ि » +b « ब »).
However, Unicode is not well suited to devanāgarī needs (it does not possess any ligature, for example). A good document should be encoded in the same order a devanāgarī text is written, and then decoded correctly by a software (especially for ligatures), but normal browser can’t. So I wrote my document as correctly as I could, that is to say that I've indicated where ligatures should be (which is Unicode compliant) but I've put the letters as one must read them, i.e. not in devanāgarī's order : to read /nopahinasti/, I wrote nophinsti (in devanāgarī, you never write an |a] : every consonant is, by default, followed by a short [a], unless there is another vowel after or before) and not nopihnist. Jamie Norrish's browser must be more recent that mine, so my document is, for him but not for me, incorrect.
Here is what one should see (with expected ligatures, in color, and correct vowels' placement) :
![]()
Here is what I see (the ligatures, here consonants sequences in the same color that their equivalents above, are not correctly interpreted but the vowels are) :
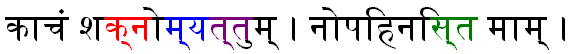
Here is what Jamie Norrish may see (maybe correct ligatures but misplaced vowels, here in red ; compare with vowels places above) :
![]()
Here is how to analyze what is written :

Text in devanāgarī script without ligatures but correctly placed vowels.
Transliteration ; italic letters are those followed by a virāma (indicated by « - ») ; note that the |i] vowel is written before the letter it follows in the pronunciation.
Text in devanāgarī script with ligatures and correctly placed vowels.
Transcription indicating the pronunciation : consonants without written vowel symbol nor virāma are read with a following [a], here transcribed by a small a above the line.
Explanations :
Every consonant is pronounced with an [a] which is not written. If the consonant is pronounced with another vowel following it, this vowel is written, but some are placed above, others below, after or before the consonant :
क = letter [k] alone, pronounced [ka]
के = letter [k] with letter [eː] above, pronounced [keː] and transcribed ke.
कु = letter [k] with letter [u] below, pronounced [ku]
की = letter [k] with letter [iː] below, pronounced [kiː] and transcribed kī.
िक = letter [k] with letter [i] before, pronounced [ki].
If the consonant mustn't be followed by an [a] and is the last letter before a punctuation (i.e. « । », kind of comma, and « ॥ », kind of dot), it must be followed by a virāma o ् placed below : अक = aka but अक् = ak.
When one must write a cluster of consonants, as kka, ksa
or ktra, it is not possible to place each letter one after the other, for these
consonants would be pronounced with an a : अकक reads akaka, not akka ;
it is possible to use a virāma, but it's not the right way : अक्क = akka.
That's what I did with the document I sent you, because Unicode does not possess the correct
ligatures symbols : kk should be written ![]() , akka
, akka ![]() and akk
and akk
![]() .
Ligatures are standalone symbols representing consonants clusters.
.
Ligatures are standalone symbols representing consonants clusters.
A good software (I.E. 5.5 can, but I don't know how) could
transform अक्क in ![]() .
.
<quote>
Assuming the transliteration is correct, the correct
character sequence is:
0928 0913 092A 0939 093F 0928 0938 0924 093F ;
<end of quote>
It is not. This sequence is displayed as ![]() by my browser, which I
read na opahanisata (i), the last symbol, an i
ि at the end of the word, being impossible to read. Without virāmas, there are too many
letters a (which are underlined) in the word but no clusters, and the i
ि are badly placed. Last point, the ओ symbol, which reads o, can only be used at
the beginning of a sequence of letters. Inside a word, its must be written ो.
by my browser, which I
read na opahanisata (i), the last symbol, an i
ि at the end of the word, being impossible to read. Without virāmas, there are too many
letters a (which are underlined) in the word but no clusters, and the i
ि are badly placed. Last point, the ओ symbol, which reads o, can only be used at
the beginning of a sequence of letters. Inside a word, its must be written ो.
This sequence could be correctly displayed only by a very smart software, able to interpret these sequences of letters.
<quote>
093F is the short i character which is displayed before the consonant
which it is pronounced after.
<end of quote>
Yes, that's why it must be written before it.
To sum up, I don't agree with Jamie Norrish : the
sequence he proposes is not correct. Maybe his browser is able to transform it into correct devanāgarī
orthography, I don't know. Anyway, what you should read on your web page is either 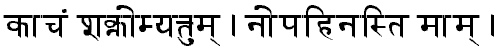 (with interpolated
ligatures), or
(with interpolated
ligatures), or  (analytic orthography).
(analytic orthography).
Regards,
Vincent Ramos / Siva