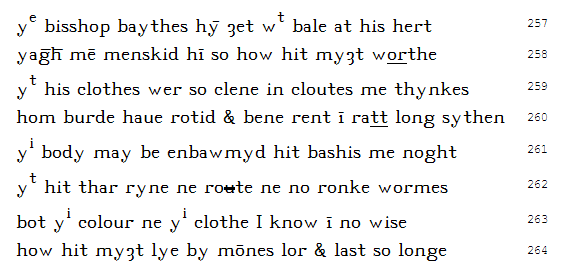
|
ye bisshop baythes hȳ ȝet wt bale at his hert 257 yag̅h̅ mē menskid hī so how hit myȝt worthe 258 yt his clothes wer so clene in cloutes me thynkes 259 hom burde haue rotid & bene rent ī ratt long sythen 260 yi body may be enbawmyd hit bashis me noght 261 yt hit thar ryne ne ro ute ne no ronke wormes262 bot yi colour ne yi clothe I know ī no wise 263 how hit myȝt lye by mōnes lor & last so longe 264
This is a Middle English alliterative poem written about 1390 by an unknown author; manuscript copy dated 1477, British Library MS Harley 2250. From J.A. Burrow and Thorlac Turville-Petre, A Book of Middle English, Blackwell Publishers, Oxford (1992).
The passage above is encoded in UTF-8 with minimal HTML markup. The manuscript includes liberal use of overlining, mostly to denote vowels followed by "m" or "n"; for example "mē" means "men". The overline is represented here by U+0304 Combining Macron, since HTML does not have a font style element for overlining as it does for underlining (<u>..</u>). The intention of the line over "gh" in line 258 is unclear, but in this case we code it with U+0305 Combining Overline (rather than Combining Macron) after "g" and after "h", because adjacent macrons do not necessarily join together. However, we don't use Combining Overline over single letters because it's too wide. If your browser does not handle the Latin letter + Combining Macron (or Overline) combination, the overline appears right of the letter with a dotted circle underneath or, if the character is not even in your browser's font, as an "unknown character" symbol. (See Notes below about future developments.)
Underlining (accomplished here by markup) is used by the copyist to identify material that is questionable and/or glossed in the margins. Also note the crossed-out letter "u" of "route" in line 262 ("<strike>u</strike>"), indicating a correction by the copyist.
The letter "ȝ" (yogh) represents "y" at the beginning of a word or between vowels ("ȝet", yet; "yȝe", eye; "faȝerest", fairest), sometimes "w" between vowels ("oȝen", own; "ȝoȝelinge", yowling), "gh" (German ich Laut) at the end of a word or before another consonant ("roȝ", rough; "myȝt", might), and in Old English "g" ("wiȝa", man; "fuȝel", bird).
The letter "y" is written in this manuscript for both "y" and "þ" (thorn, modern "th"; "yagh" = "þagh" = "þaȝ", meaning "though"). The letter "u" is written both for itself and for "v" ("haue" = "have"). No punctuation is used.
Superscripts (represented here by markup) are sometimes used to denote abbreviation (wt = "with", yt = "that") and other times in common short words such as ye or yi (alternative spellings of "þe" = "the").
Although markup should be used for superscript letters, a couple of them (such as "i" and "n") have been encoded directly in Unicode for round-trip compatibility with other character sets. Thus, although it would not be considered good practice, "yi" (y<sup>i</sup>) could also be encoded as "y" followed by U+2071 Superscript Small Letter "i": "yⁱ" (Unicode 3.1 and later)
For reference, here are the special letters of Old and Middle English (not all of which are used in the sample above), together with their unicode values:
Name Capital Small Origin Description Ash U+00C6 Æ U+00E6 æ Latin As in modern English "hat" Thorn U+00DE Þ U+00FE þ Futharc þorn: modern "th" (survives in Icelandic) Eth U+00D0 Ð U+00F0 ð Old Irish Eð, þæt: modern "th" (survives in Icelandic) Yogh U+021C Ȝ U+021D ȝ Old Irish Y, gh, g, w (not to be confused with Ezh) Wynn U+01F7 Ƿ U+01BF ƿ Futharc (or Wen): modern "w"
If you don't know how to insert Unicode characters directly into your Web document, you can use HTML Numeric Character References (NCRs); refer to THIS TABLE for a (long) list of Unicode characters and the corresponding NCRs. For example to write "hȳ", you can put the following in your HTML file:
hyİ
Tools Used To Make This Page: The Kermit 95 2.0 terminal emulator to a Unix host with the GNU EMACS text editor, version 21.2. In EMACS I select UTF-8 as my file, keyboard, and terminal coding system. In Kermit, I choose UTF-8 as my terminal character set and then enter any non-ASCII values that are not directly accessible on my keyboard by their 4-digit hexadecimal values in the Alt-N dialog (press Alt-N, enter four hex digits), as illustrated HERE. To view obscure characters such as Yogh and Wynn in Kermit's terminal emulation screen, I use a well-populated monospace font such as Everson Mono Terminal or Agfa/Monotype Andale Mono WT J.
Displaying This Page: The passage did not display correctly in Windows XP with its normal collection of fonts, in either Netscape 6.2 or MSIE 6.0: in both cases the combining macrons and overlines appeared as spacing characters, and in MSIE the Yogh and Wynn characters were missing. However, upon installing James Kass's Code2000 font and configuring the browsers to use it, the passage displayed correctly, as shown in the following screen shot:
So did the "y" + U+2071 repesentation [yⁱ] of "þe".
Thanks to James Kass, Tex Texin, and Ken Whistler for help with this page.
U+035D COMBINING DOUBLE BREVE
U+035E COMBINING DOUBLE MACRON
U+035F COMBINING DOUBLE LOW LINE
for various transcriptions, including common English dictionary pronunciation guide usages. Once these find their way into fonts, the preferred representation to use for the gh-digraph-overlined would be:
g, combining-double-macron, h
How long it will it take for the fonts and browsers to catch up on those forms is another question! Watch this space:
yag͞h mē menskid hī so how hit myȝt worthe 258
Also see:
[ UTF-8 Sampler ] [ Unicode Consortium ] [ Code2000 ] [ Kermit 95 ] [ Kermit Home ]